一. 如何划分物理执行图
上一篇博客介绍的逻辑执行图表示的是数据上的依赖,不是task的执行图。在Hadoop中,整个数据流是固定的,用户只需要填充map和reduce函数即可。Spark面对的事更复杂的数据处理流程,数据依赖更加灵活,很难将数据流和物理task简单地统一在一起。因此,Spark将数据流和具体task的执行流程分开,并设计算法将逻辑执行图转换为task物理执行图
给定一个数据依赖图,如何划分stage,并确定task和类型和个数呢?
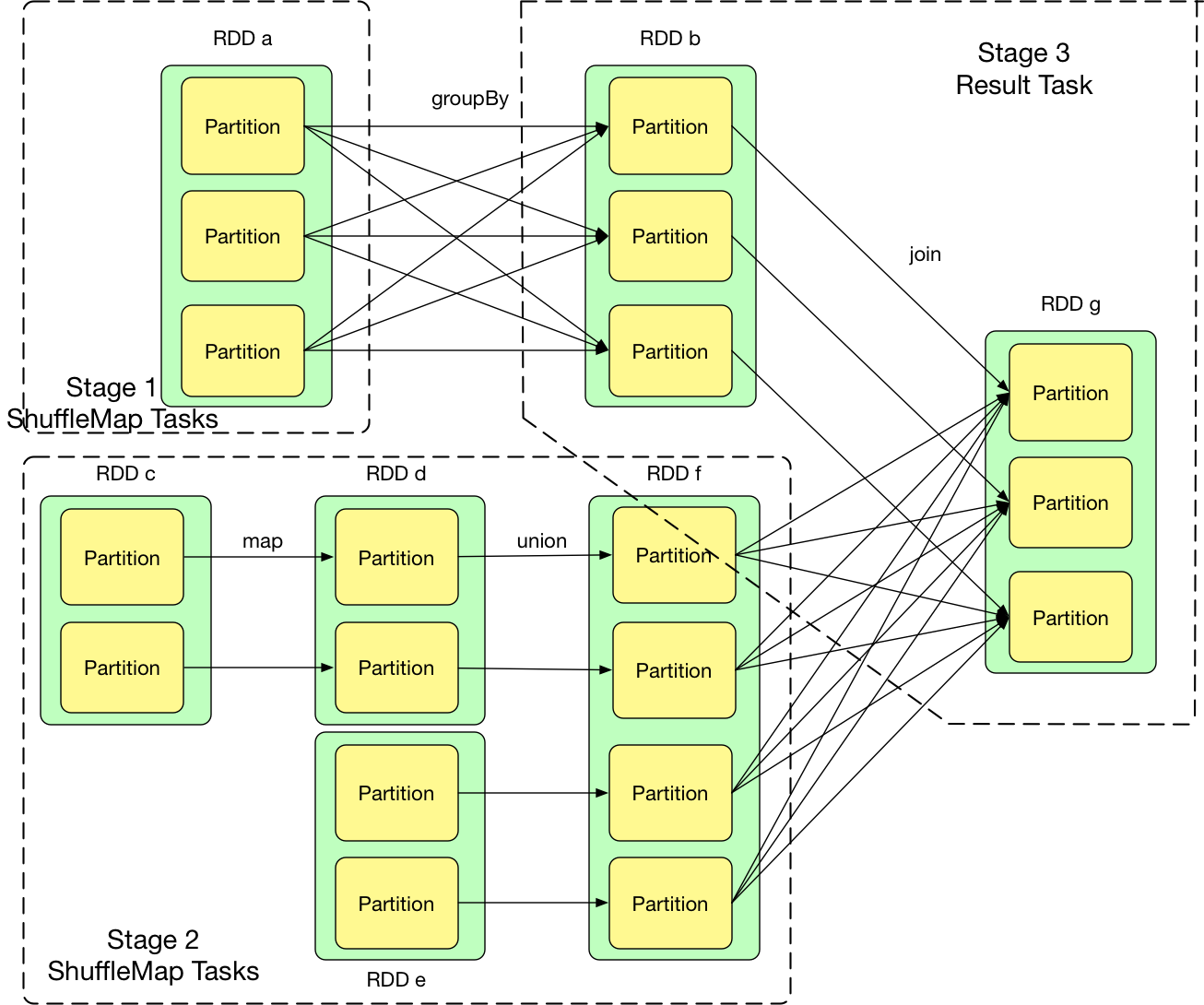
对于NarrowDependency关联的一个或多个RDD,可以用pipeline模式进行计算,不需要存储中间结果。以上一篇博客介绍的wordcount来说,sc.textFile生成的hadoopRDD中持有读取HadoopFile的迭代器,之后的flatMap和map生成的RDD中只有计算逻辑。从record粒度来说,flatMap对hadoopRDD读取的每一个record执行了f(record)操作,之后map操作对之前的结果又执行了g(f(record))操作。 对于ShuffleDependency关联的RDD,需要计算之前pipeline形成的计算链,并且子RDD通过网络拉取计算好的数据。
通过上面的分析,不难想出可以用如下的方法划分:从后往前推算,遇到ShuffleDependency就断开,遇到NarrowDependency就将其加入该stage。每个stage里面task的数据由该stage最后一个RDD中的partition数量决定 如果stage最后要产生result,那么该stage里面的task都是ResultTask,否则都是ShuffleMapTask,之所以称为 ShuffleMapTask 是因为其计算结果需要 shuffle 到下一个 stage,本质上相当于 MapReduce 中的 mapper。
二. 物理图的执行
生成stage和task以后,下一个问题就是task如何执行来生成result?
回想 pipeline 的思想是 数据用的时候再算,而且数据是流到要计算的位置的。Result 产生的地方的就是要计算的位置,要确定 “需要计算的数据”,我们可以从后往前推,需要哪个 partition 就计算哪个 partition,如果 partition 里面没有数据,就继续向前推,形成 computing chain。这样推下去,结果就是:需要首先计算出每个 stage 最左边的 RDD 中的某些 partition
由此可以看出,computing chain 从后到前建立,而实际计算出的数据从前到后流动,而且计算出的第一个 record 流动到不能再流动后,再计算下一个 record。这样,虽然是要计算后续 RDD 的 partition 中的 records,但并不是要求当前 RDD 的 partition 中所有 records 计算得到后再整体向后流动
代码实现:
每个 RDD 包含的 etDependency负责确立 RDD 的数据依赖,compute方法负责接收 parent RDDs 或者 data block 流入的 records,进行计算,然后输出 record。经常可以在 RDD 中看到这样的代码firstParent[T].iterator(split, context).map(f)。firstParent 表示该 RDD 依赖的第一个parent RDD,iterator表示 parentRDD 中的records是一个一个流入该 RDD 的,map(f) 表示每流入一个recod就对其进行 f(record) 操作,输出 record。为了统一接口,这段compute仍然返回一个 iterator,来迭代 map(f) 输出的records。
三. 生成并提交Job
前面介绍了逻辑和物理执行图的生成原理,那么,怎么触发 job 的生成?已经介绍了 task,那么 job 是什么?
用户的driver程序一旦出现action算子(e.g. collect(), first(), take()),就会生成一个job,比如foreach()会调用sc.runJob(this, (iter: Iterator[T]) => iter.foreach(f)),向DAGSchedule提交job。
每一个job包含n个stage,最后一个stage产生result。在job提交过程中,DAGScheduler会首先划分stage,然后先提交无parent stage的stages,并在提交过程中确定该stage的task个数及类型,并提交具体的task。无parent staged的stage提交完后,依赖该stage的stage才能够提交。从stage和task的执行角度来讲,一个stage的parent stages执行完后,该stage才能执行
程序细节
- action算子会调用
sc.runJob(this, (iter: Iterator[T]) => iter.someFunction)来向SparkContext提交作业。这里this代表的是finalRDD(最后一个RDD) - SparkContext中的runJob方法会根据finalRDD中存在的partition个数和类型new出将来要持有的result数据
Array[U](partitions.size) - SparkContext最后通过内部的DAGScheduler提交作业
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, allowLocal, resultHandler, localProperties.get)。dagScheduler主要作用是负责切分stage,然后转换为TaskSet给TaskScheduler,taskScheduler再提交作业给Executor - dagScheduler中通过
submitJob(rdd, func, partitions, callSite, allowLocal, resultHandler, properties)来提交作业。 - dagScheduler的submit方法中首先得到一个jobId,然后将数据封装到事件中,将事件放入到eventProcessLoop阻塞队列中
eventProcessLoop.post(JobSubmitted(jobId, rdd, func2, partitions.toArray, allowLocal, callSite, waiter, properties))。 - 这个阻塞队列在dagScheduler的构造方法中被启动,所以收到事件后,会启动该事件对应的任务(典型的事件驱动模型)即
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, allowLocal, callSite, listener, properties) dagScheduler.handleJobSubmitted方法中首先调用finalStage = newStage()来划分stage,然后通过submitStage(finalStage)提交stage。submitStage()通过submitMissingTasks()递归的提交stage(先提交最上层的parent stage,然后逐层往下),在submitMissingTasks()方法中会调用TaskScheduler的submitTasks方法来提交TaskSet,taskScheduler.submitTasks(new TaskSet(tasks.toArray, stage.id, stage.newAttemptId(), stage.jobId, properties))- taskSceduler的submitTasks方法会向driverActor发送ReiveOffers消息,driverActor收到ReiveOffers消息后会向executorActor发送序列化好的Task,
executorActor ! LaunchTask(new SerializableBuffer(serializedTask))