一. WordCount Job逻辑执行过程
下图以WordCount为例:
sc.textFile(...).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _, 2).collect
在写 Spark 程序时,头脑中会生成如下的 Job 逻辑执行图。实际代码中,生成的 RDD 数量远不止这些,例如再执行 reduceByKey 时,底层调用的是 combineByKeyWithClassTag,会先在 map 端进行 mergeValue,合并相同 key 对应的 value 得到 MapPartitionsRDD,然后 Shuffle 得到 MapPartitionsRDD,再进行 reduce(通过 aggregate + mapPartitions() 操作来实现)得到 MapPartitionsRDD
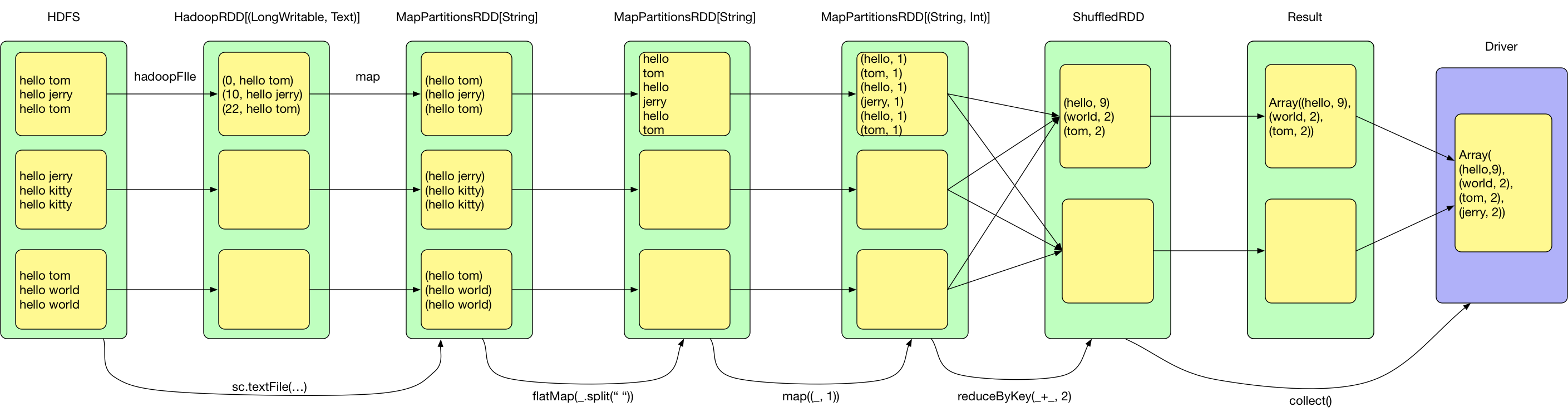
WordCount 的 Job 执行过程如上所示,通常 Job 任务的执行会经过如下四个步骤:
- 从数据源(可以是本地 file,内存数据结构,HDFS,HBase 等)读取数据创建最初的 RDD
- 对 RDD 进行一系列的 transformation() 操作,每一个 transformation() 会产生一个或多个包含不同类型 T 的 RDD[T]。T 可以是 Scala 里面的基本类型或数据结构,不限于 (K, V)。但如果是 (K, V),K 不能是 Array 等复杂类型(因为难以在复杂类型上定义 partition 函数)
- 对最后的 final RDD 进行 action() 操作,每个 partition 计算后产生结果 result
- 将 result 回送到 driver 端,进行最后的 f(list[result]) 计算
二. 逻辑执行图的生成
逻辑执行图实际上是数据计算链,每个RDD里有compute方法,负责接收来自上一个RDD或者数据源的input records,执行transformation中的计算逻辑,输出records
以map(_, 1)为例
def map[U: ClassTag](f: T => U): RDD[U] = {
val cleanF = sc.clean(f)
// 使用用户定义的计算逻辑传生成一个新的MapPartitionsRDD
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
prev: RDD[T],
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator)
preservesPartitioning: Boolean = false)
/*
def this(@transient oneParent: RDD[_]) =
this(oneParent.context , List(new OneToOneDependency(oneParent)))
*/
// 调用父类的构造方法
extends RDD[U](prev) {
// 默认不保存父RDD的分区器
override val partitioner = if (preservesPartitioning) firstParent[T].partitioner else None
override def getPartitions: Array[Partition] = firstParent[T].partitions
// compute中只有计算逻辑,不保存数据
override def compute(split: Partition, context: TaskContext) =
f(context, split.index, firstParent[T].iterator(split, context))
}
在new MapPartitionsRDD中将将用户定义的计算逻辑封装为f:(context, pid, iter) => iter.map(cleanF),再看MapPartitionsRDD的compute方法f(context, split.index, firstParent[T].iterator(split, context))。从这不难看出,用户自定的计算逻辑作用于上一个RDD的records迭代器上,每个RDD只保存计算逻辑,不保存数据。
回顾下上一篇所讲的两种RDD创建方式
- Parallelizing an existing collection in your driver program
- Referencing a dataset in an external storage system, such as a shared filesystem, HDFS, HBase, or any data source offering a Hadoop InputFormat
可以大致了解Spark的数据执行过程(逻辑上的,和真实计算过程有出入),还是以上面的wordCount为例。在HadoopRDD的compute生成了一个从Hadoop File中读取数据的迭代器,flatMap和map的compute中含有作用在迭代器上的计算逻辑。当遇到shuffle算子reduceByKey时,会进行计算(pipeline模式:数据用的时候再算,而且数据是流到要计算的位置),并将结果形成新的records迭代器,进行下一步的map操作,最后再collect回收结果到dirver端
在写程序时在头脑中形成Job逻辑执行图是至关重要的,在形成逻辑执行图时往往需要考虑以下两点
- 如何产生RDD,执行过程中会生成哪些RDD
- RDD之间的依赖关系
如何产生RDD,执行过程中会生成哪些RDD
实际代码中很多transformation会产生多个RDD,比如distinct操作实际调用了多个transformationmap(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)。
但我们在考虑问题的时候,往往可以忽略这些中间生成的RDD,单从数据变换的角度认为每个transformation操作只返回了一个新的RDD
建立RDD之间的依赖关系
父RDD和子RDD的依赖关系可以分为3种,OneToOneDepency、RangeDependency、ShuffleDependency,也可以将前2者划分为NarrowDependency,后面单独分为ShuffleDependency。 ShuffleDependency类似于MapReduce中的shuffle(mapper 将其 output 进行 partition,然后每个 reducer 会将所有 mapper 输出中属于自己的 partition 通过 HTTP fetch 得到)