一. RDD简介
What is Spark RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可以并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性
RDD的属性
Internally, each RDD is characterized by five main properties
-
A list of partitions. RDD由一系列partition组成,对RDD来说,每个partition都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定partition个数,如果没有指定,默认采用程序所分配到的Cpu Core的数量
-
A function for computing each split. RDD的计算是以分片(split)为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果
-
A list of dependencies on other RDDs. RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算
-
Optionally, a
Partitionerfor key-value RDDs. 分区器作用于k,v格式的RDD上,当前Spark中实现了两种类型的分区器,一个是基于哈希的HashPartitioner,另一个是基于范围的RangePartitioner -
Optionally, a list of preferred location to compute each split on. RDD提供一系列最佳计算位置
如何创建RDD
有两种创建RDD的方式
-
Parallelizing an existing collection in your driver program
-
Referencing a dataset in an external storage system, such as a shared filesystem, HDFS, HBase, or any data source offering a Hadoop InputFormat
RDD概念图
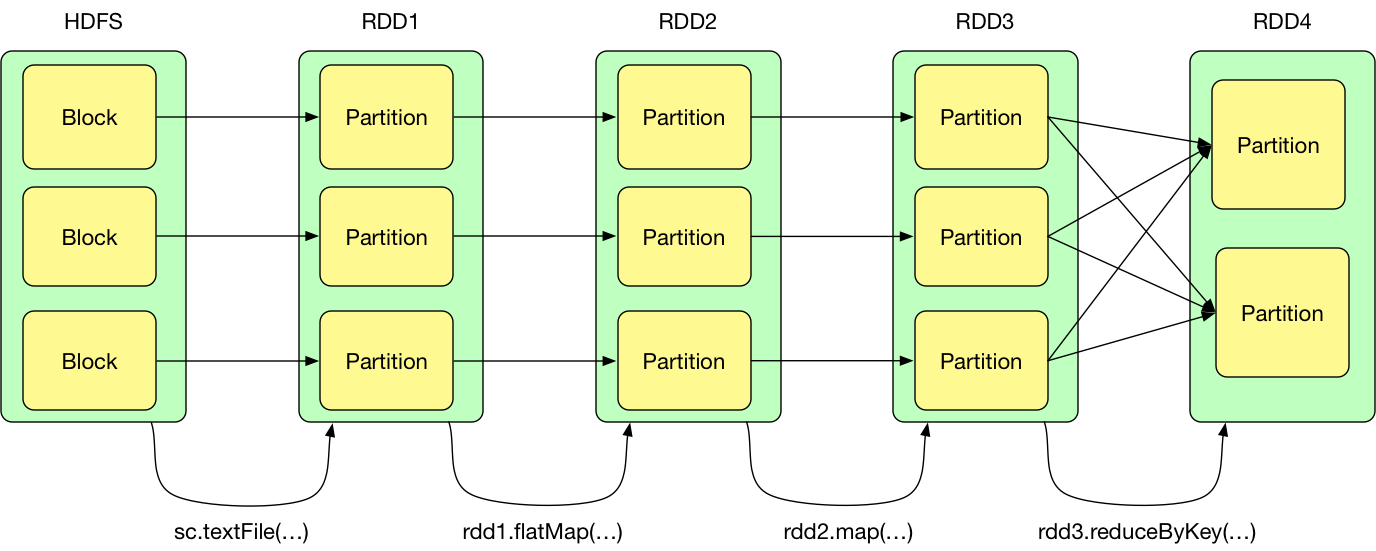
二. RDD的依赖关系
RDD和它依赖的父RDD的关系有两种不同的类型,即shuffle依赖(shuffle dependency)和窄依赖(narrow dependency)
窄依赖
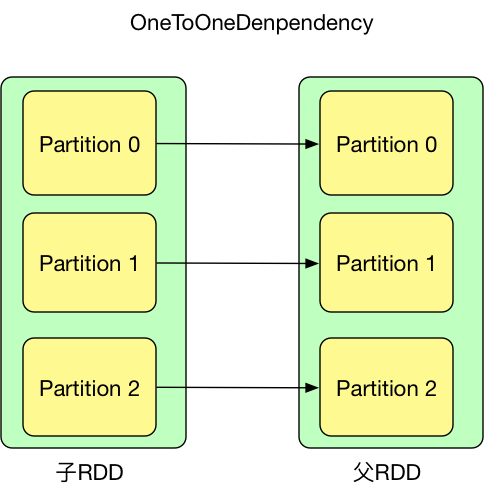
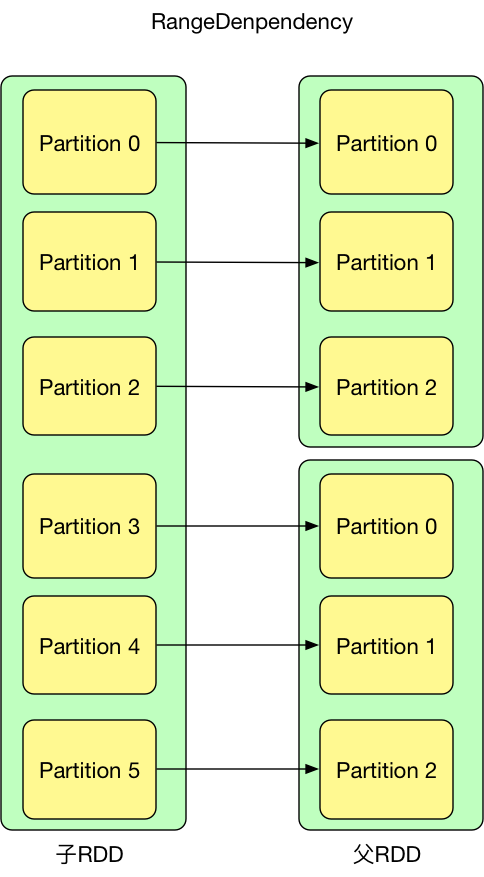
如果RDD与上游RDD分区是一对一的关系,那么RDD和其上游RDD之间的依赖关系属于窄依赖(NarrowDependency)。NarrowDependency一共有两个子类,分别为
- OneToOneDependency
- RangeDependency
shuffle依赖
RDD与上游RDD的分区如果不是一对一的关系,或者RDD的分区依赖于上游RDD的多个分区,那么这种依赖关系就叫做Shuffle依赖
三. RDD缓存机制
cache
-
cache作用 cache 能够让重复数据在同一个 application 中的 jobs 间共享。RDD的cache()方法其实调用的就是persist方法,缓存策略均为MEMORY_ONLY
-
Application如何读取cache 下次计算(一般是同一 application 的下一个 job 计算)时如果用到 cached RDD,task 会直接去 blockManager 的 memoryStore 中读取。具体地讲,当要计算某个 rdd 中的 partition 时候(通过调用 rdd.iterator())会先去 blockManager 里面查找是否已经被 cache 了,如果 partition 被 cache 在本地,就直接使用 blockManager.getLocal() 去本地 memoryStore 里读取。如果该 partition 被其他节点上 blockManager cache 了,会通过 blockManager.getRemote() 去其他节点上读取
persist
- persist持久化级别
object StorageLevel { val NONE = new StorageLevel(false, false, false, false) val DISK_ONLY = new StorageLevel(true, false, false, false) val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2) val MEMORY_ONLY = new StorageLevel(false, true, false, true) val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2) val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false) val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2) // 如果数据在内存中放不下,则溢写到磁盘上 val MEMORY_AND_DISK = new StorageLevel(true, true, false, true) val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2) // 如果数据在内存中放不下,则溢写到磁盘上,在内存中存放序列化后的数据 val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false) val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2) val OFF_HEAP = new StorageLevel(false, false, true, false) }Scala和Java中,默认情况下persist()会把数据以序列化的形式缓存在JVM的堆空间中
需要注意的情况
-
如果某个需要cache的数据大小超过executor-memory,spark并不会报错,Exectutor会缓存部分数据,缓存不了的数据在计算时会重新拉取
-
如果缓存的数据太多,内存中装不下,Spark会自动利用最近最少使用(LRU)缓存策略把最老的分区从内存中移除。对于仅把数据存放在内存的缓存级别,下一次要用到已经被移除的分区时,这些分区就需要重新计算。但是对于使用内存与磁盘的缓存级别的分区来说,被移除的分区都会写入磁盘
四. CheckPoint
checkPoint与cache区别
cache把 RDD 计算出来然后放在内存中, 但是RDD 的依赖链也不能丢掉, 当某个点某个 executor 宕了, 上面cache 的RDD就会丢掉, 需要通过依赖链重新计算出来;而 checkpoint 是把 RDD 保存在 HDFS中, 是多副本可靠存储,所以依赖链就可以丢掉了,就斩断了依赖链,因为checkpoint是需要把 job 重新从头算一遍, 最好先cache一下, checkpoint就可以直接保存缓存中的 RDD 了, 就不需要重头计算一遍了, 对性能有极大的提升。
这里值得注意的是:cache 机制是每计算出一个要 cache 的 partition 就直接将其 cache 到内存了。但 checkpoint 没有使用这种第一次计算得到就存储的方法,而是等到 job 结束后另外启动专门的 job 去完成 checkpoint 。也就是说需要 checkpoint 的 RDD 会被计算两次。因此,在使用 rdd.checkpoint() 的时候,建议加上 rdd.cache(),这样第二次运行的 job 就不用再去计算该 rdd 了,直接读取 cache 写磁盘。
checkPoint和persist区别
rdd.persist(StorageLevel.DISK_ONLY) 与 checkpoint 区别的是:前者虽然可以将 RDD 的 partition 持久化到磁盘,但该 partition 由 blockManager 管理。一旦 driver program 执行结束,也就是 executor 所在进程 CoarseGrainedExecutorBackend stop,blockManager 也会 stop,被 cache 到磁盘上的 RDD 也会被清空(整个 blockManager 使用的 local 文件夹被删除)。而 checkpoint 将 RDD 持久化到 HDFS 或本地文件夹,如果不被手动 remove 掉( 话说怎么 remove checkpoint 过的 RDD? ),是一直存在的,也就是说可以被下一个 driver program 使用,而 cached RDD 不能被其他 dirver program 使用
如何使用checkPoint
// 首先需要设置checkpoint目录
sc.setCheckpointDir("hdfs://10.211.55.7:8020/sparkCheckPointTestDir")
val rdd1 = sc.textFile("....")
rdd1.checkpoint
rdd1.flapMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).saveAsTextFile("...")
// 再一次使用rdd1时会从checkPointDir中读取数据
rdd1.map(...)