说明:
- 源码版本:hadoop2.6.5
- 资源调度模式:Local
- 客户端:本机(Mac)
- 文件系统:HDFS
- 使用debug的模式跟踪代码,获取变量值,文本使用{variable value }表示debug模式下获得的变量值。客户端代码是最简单的wordcount
一. Job提交流程图
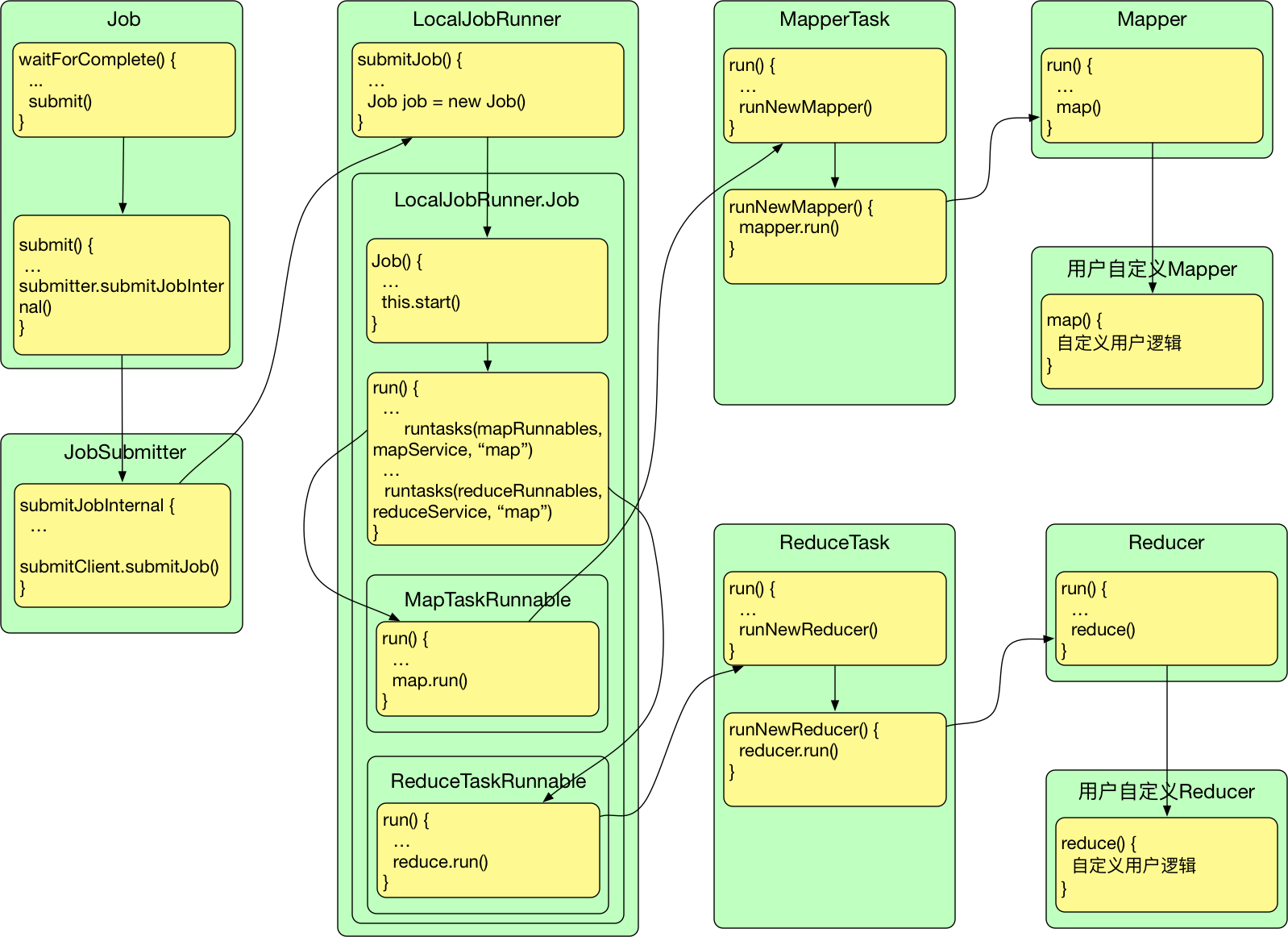
二. Job提交源码追踪
- 在客户端代码中,是通过job.waitForCompletion提交的作业的。
public boolean waitForCompletion(boolean verbose ) throws IOException, InterruptedException, ClassNotFoundException { if (state == Job.JobState.DEFINE) { // 通过submit方法来提交作业 submit(); } if (verbose) { // 打印作业的进度 monitorAndPrintJob(); } else { // get the completion poll interval from the client. int completionPollIntervalMillis = Job.getCompletionPollInterval(cluster.getConf()); while (!isComplete()) { try { Thread.sleep(completionPollIntervalMillis); } catch (InterruptedException ie) { } } } return isSuccessful(); } - waitForCompletion内部是通过submit提交的
public void submit() throws IOException, InterruptedException, ClassNotFoundException { ensureState(Job.JobState.DEFINE); // 方法中检测是否手动设置了使用旧的API // 默认是使用新的API setUseNewAPI(); // connect方法中会根据配置创建出cluster对象 connect(); // 根据文件系统和客户端创建出submitter(提交者)对象 // submitter中持有2个重要的对象 // 1. jtFS --> 文件系统 {LocalFileSystem} // 2. submitClient --> 和jobTracker通信的对象 {LocalJobRunner} final JobSubmitter submitter = getJobSubmitter(cluster.getFileSystem(), cluster.getClient()); status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() { public JobStatus run() throws IOException, InterruptedException, ClassNotFoundException { // 提交作业 return submitter.submitJobInternal(Job.this, cluster); } }); state = Job.JobState.RUNNING; LOG.info("The url to track the job: " + getTrackingURL()); }submitClient是实现ClientProtocol接口的对象,ClientProtocol规定了客户端和资源调度器之间的RPC通信协议,关于RPC通信,可以看之前写的另一篇博客。ClientProtocol的实现类有LocalJobRunner和YARNRunner,分别对应了两种资源调度框架。
- 进入submitter.submitJobInternel方法中
JobStatus submitJobInternal(Job job, Cluster cluster) throws ClassNotFoundException, InterruptedException, IOException { //validate the jobs output specs // 检查作业的输出路径,保证输出路径不为空并且 not already there checkSpecs(job); // getConfiguration会默认读取以下几个文件 // core-default.xml core-site.xml mapred-default.xml mapred-site.xml // yarn-default.xml yarn-site.xml hdfs-default.xml hdfs-site.xml Configuration conf = job.getConfiguration(); addMRFrameworkToDistributedCache(conf); // 获得Job提交的部分路径(后面会和JobId拼接成完整路径) // {file:/tmp/hadoop-spencer/mapred/staging/root1128794791/.staging} Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf); //configure the command line options correctly on the submitting dfs // 获得本地hostname和ip {Spencers-MacBook-Pro.local/192.168.254.55} InetAddress ip = InetAddress.getLocalHost(); if (ip != null) { submitHostAddress = ip.getHostAddress(); submitHostName = ip.getHostName(); conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName); conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress); } // JobClient和JobTracker RPC通信 获得jobId {job_local159099713_0001} JobID jobId = submitClient.getNewJobID(); job.setJobID(jobId); // 获得Job提交的路径 {file:/tmp/hadoop-spencer/mapred/staging/root1128794791/.staging/job_local1128794791_0001} Path submitJobDir = new Path(jobStagingArea, jobId.toString()); JobStatus status = null; try { // 在配置文件中设置job路径,用户名 conf.set(MRJobConfig.USER_NAME, UserGroupInformation.getCurrentUser().getShortUserName()); conf.set("hadoop.http.filter.initializers", "org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer"); conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString()); LOG.debug("Configuring job " + jobId + " with " + submitJobDir + " as the submit dir"); // get delegation token for the dir TokenCache.obtainTokensForNamenodes(job.getCredentials(), new Path[] { submitJobDir }, conf); populateTokenCache(conf, job.getCredentials()); // generate a secret to authenticate shuffle transfers if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) { KeyGenerator keyGen; try { int keyLen = CryptoUtils.isShuffleEncrypted(conf) ? conf.getInt(MRJobConfig.MR_ENCRYPTED_INTERMEDIATE_DATA_KEY_SIZE_BITS, MRJobConfig.DEFAULT_MR_ENCRYPTED_INTERMEDIATE_DATA_KEY_SIZE_BITS) : SHUFFLE_KEY_LENGTH; keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM); keyGen.init(keyLen); } catch (NoSuchAlgorithmException e) { throw new IOException("Error generating shuffle secret key", e); } SecretKey shuffleKey = keyGen.generateKey(); TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(), job.getCredentials()); } // 将作业运行时需要的资源(作业jar文件,配置文件和计算所得的输入分片) // 复制到jobtracker的文件系统中(路径为submitJobDir) copyAndConfigureFiles(job, submitJobDir); Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir); // Create the splits for the job LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir)); // 写入map的切片信息到submitJobDir // 会在submitJobFile {file:/tmp/hadoop-spencer/mapred/staging/root1128794791/.staging/job_local1128794791_0001} // 路径下生成job.split .job.split.crc job.splitmetainfo .job.splitmeatainfo.crc 四个文件 int maps = writeSplits(job, submitJobDir); conf.setInt(MRJobConfig.NUM_MAPS, maps); LOG.info("number of splits:" + maps); // write "queue admins of the queue to which job is being submitted" // to job file. String queue = conf.get(MRJobConfig.QUEUE_NAME, JobConf.DEFAULT_QUEUE_NAME); AccessControlList acl = submitClient.getQueueAdmins(queue); conf.set(toFullPropertyName(queue, QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString()); // removing jobtoken referrals before copying the jobconf to HDFS // as the tasks don't need this setting, actually they may break // because of it if present as the referral will point to a // different job. TokenCache.cleanUpTokenReferral(conf); if (conf.getBoolean( MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED, MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) { // Add HDFS tracking ids ArrayList<String> trackingIds = new ArrayList<String>(); for (Token<? extends TokenIdentifier> t : job.getCredentials().getAllTokens()) { trackingIds.add(t.decodeIdentifier().getTrackingId()); } conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS, trackingIds.toArray(new String[trackingIds.size()])); } // Set reservation info if it exists ReservationId reservationId = job.getReservationId(); if (reservationId != null) { conf.set(MRJobConfig.RESERVATION_ID, reservationId.toString()); } // Write job file to submit dir // 将job的配置信息写入submitJobFile路径下 // 会在submitJobFile {file:/tmp/hadoop-spencer/mapred/staging/root1128794791/.staging/job_local1128794791_0001} // 路径下生成job.xml和 .job.xml.crc 两个文件 writeConf(conf, submitJobFile); // // Now, actually submit the job (using the submit name) // printTokens(jobId, job.getCredentials()); // 前面提过submitClient是ClientProtocol实现类的对象,这里submitClient是LocalJobRunner //(YARNRunner代码量太大了,不好调试,等以后更全面了解Yarn资源调度细节再分析源码吧QAQ) status = submitClient.submitJob( jobId, submitJobDir.toString(), job.getCredentials()); if (status != null) { return status; } else { throw new IOException("Could not launch job"); } } finally { if (status == null) { LOG.info("Cleaning up the staging area " + submitJobDir); if (jtFs != null && submitJobDir != null) jtFs.delete(submitJobDir, true); } } }有关map是如何切片的可以参考另一篇(博客)[http://blog.csdn.net/u010010428/article/details/51469994]
- 继续查看LocalJobRunner是如何submitJob的
public org.apache.hadoop.mapreduce.JobStatus submitJob( org.apache.hadoop.mapreduce.JobID jobid, String jobSubmitDir, Credentials credentials) throws IOException { job = new Job(JobID.downgrade(jobid), jobSubmitDir); job.setCredentials(credentials); return job.status; } - 继续查看new Job中做了哪些事情
public Job(JobID jobid, String jobSubmitDir) throws IOException { // 获得job提交的路径 systemJobDir {file:/tmp/hadoop-spencer/mapred/staging/root1128794791/.staging/job_local1128794791_0001} this.systemJobDir = new Path(jobSubmitDir); // 获得job.xml路径 systemJobFile {file:/tmp/hadoop-spencer/mapred/staging/root1128794791/.staging/job_local1128794791_0001/job.xml} this.systemJobFile = new Path(systemJobDir, "job.xml"); // id {job_local1128794791_0001} this.id = jobid; // 根据job.xml的内容生成JobConf JobConf conf = new JobConf(systemJobFile); this.localFs = FileSystem.getLocal(conf); String user = UserGroupInformation.getCurrentUser().getShortUserName(); // localJobDir {file:/tmp/hadoop-spencer/mapred/local/localRunner/root/job_local1128794791_0001} this.localJobDir = localFs.makeQualified(new Path( new Path(conf.getLocalPath(jobDir), user), jobid.toString())); // localJobFile {file:/tmp/hadoop-spencer/mapred/local/localRunner/root/job_local1128794791_0001/job_local1128794791_0001.xml} this.localJobFile = new Path(this.localJobDir, id + ".xml"); // Manage the distributed cache. If there are files to be copied, // this will trigger localFile to be re-written again. localDistributedCacheManager = new LocalDistributedCacheManager(); localDistributedCacheManager.setup(conf); // Write out configuration file. Instead of copying it from // systemJobFile, we re-write it, since setup(), above, may have // updated it. // 将配置文件job.xml 拷贝到localJobDir下 // 将在file:/tmp/hadoop-spencer/mapred/local/localRunner/root/job_local1128794791_0001下生成以下两个文件 // job_local1128794791_0001.xml 和 .job_local1128794791_0001.xml.crc OutputStream out = localFs.create(localJobFile); try { conf.writeXml(out); } finally { out.close(); } // 根据.xml文件生成新的JobConf配置对象job,这里名字起为job真的好吗:) this.job = new JobConf(localJobFile); // Job (the current object) is a Thread, so we wrap its class loader. if (localDistributedCacheManager.hasLocalClasspaths()) { setContextClassLoader(localDistributedCacheManager.makeClassLoader( getContextClassLoader())); } profile = new JobProfile(job.getUser(), id, systemJobFile.toString(), "http://localhost:8080/", job.getJobName()); status = new JobStatus(id, 0.0f, 0.0f, JobStatus.RUNNING, profile.getUser(), profile.getJobName(), profile.getJobFile(), profile.getURL().toString()); // jobs是一个hashMap // 目前size为1 {"job_local1128794791_0001" -> "Thread[Thread-17,5,main]"} jobs.put(id, this); // 开启线程启动job的run方法 this.start(); } - 接着看下Job的run方法
public void run() { // jobID {job_local1128794791_0001} JobID jobId = profile.getJobID(); JobContext jContext = new JobContextImpl(job, jobId); org.apache.hadoop.mapreduce.OutputCommitter outputCommitter = null; try { // outputCommitter {FileOutputCommitter} outputCommitter = createOutputCommitter(conf.getUseNewMapper(), jobId, conf); } catch (Exception e) { LOG.info("Failed to createOutputCommitter", e); return; } try { // 从systemJobDir中获得job.split信息,创建出TaskSplitMetaInfo对象 JobSplit.TaskSplitMetaInfo[] taskSplitMetaInfos = SplitMetaInfoReader.readSplitMetaInfo(jobId, localFs, conf, systemJobDir); // 获取reduce task数量 // numReduceTasks {1} int numReduceTasks = job.getNumReduceTasks(); outputCommitter.setupJob(jContext); status.setSetupProgress(1.0f); // 创建Map的输出对象 Map<TaskAttemptID, MapOutputFile> mapOutputFiles = Collections.synchronizedMap(new HashMap<TaskAttemptID, MapOutputFile>()); // 每一个切片建立MapTaskRunnable对象,并加入集合 List<LocalJobRunner.Job.RunnableWithThrowable> mapRunnables = getMapTaskRunnables( taskSplitMetaInfos, jobId, mapOutputFiles); initCounters(mapRunnables.size(), numReduceTasks); // 创建线程池,用的是Executor的newFiexedThreadPool方法 ExecutorService mapService = createMapExecutor(); // 启动线程池,运行MapTaskRunnable中的run方法 // MapTaskRunnable的run方法中会调用MapTask的run方法 runTasks(mapRunnables, mapService, "map"); try { if (numReduceTasks > 0) { // 相同方式创建,启动ReduceTaskRunnable List<LocalJobRunner.Job.RunnableWithThrowable> reduceRunnables = getReduceTaskRunnables( jobId, mapOutputFiles); ExecutorService reduceService = createReduceExecutor(); runTasks(reduceRunnables, reduceService, "reduce"); } } finally { for (MapOutputFile output : mapOutputFiles.values()) { output.removeAll(); } } // delete the temporary directory in output directory outputCommitter.commitJob(jContext); status.setCleanupProgress(1.0f); if (killed) { this.status.setRunState(JobStatus.KILLED); } else { this.status.setRunState(JobStatus.SUCCEEDED); } JobEndNotifier.localRunnerNotification(job, status); } catch (Throwable t) { try { outputCommitter.abortJob(jContext, org.apache.hadoop.mapreduce.JobStatus.State.FAILED); } catch (IOException ioe) { LOG.info("Error cleaning up job:" + id); } status.setCleanupProgress(1.0f); if (killed) { this.status.setRunState(JobStatus.KILLED); } else { this.status.setRunState(JobStatus.FAILED); } LOG.warn(id, t); JobEndNotifier.localRunnerNotification(job, status); } finally { try { fs.delete(systemJobFile.getParent(), true); // delete submit dir localFs.delete(localJobFile, true); // delete local copy // Cleanup distributed cache localDistributedCacheManager.close(); } catch (IOException e) { LOG.warn("Error cleaning up "+id+": "+e); } } } - 接着我们看下运行mapTask和reduceTask的runTasks中的代码
private void runTasks(List<LocalJobRunner.Job.RunnableWithThrowable> runnables, ExecutorService service, String taskType) throws Exception { // Start populating the executor with work units. // They may begin running immediately (in other threads). // 从runnables集合中取出mapTask任务,放入线程池中运行 for (Runnable r : runnables) { // 加入线程池,执行mapTask的run方法 service.submit(r); } try { service.shutdown(); // Instructs queue to drain. // Wait for tasks to finish; do not use a time-based timeout. // (See http://bugs.sun.com/bugdatabase/view_bug.do?bug_id=6179024) LOG.info("Waiting for " + taskType + " tasks"); service.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS); } catch (InterruptedException ie) { // Cancel all threads. service.shutdownNow(); throw ie; } LOG.info(taskType + " task executor complete."); // After waiting for the tasks to complete, if any of these // have thrown an exception, rethrow it now in the main thread context. for (LocalJobRunner.Job.RunnableWithThrowable r : runnables) { if (r.storedException != null) { throw new Exception(r.storedException); } } }runTasks主要就是创建线程启动Map/Reduce TaskRunnable的run方法(因为MapTask和ReduceTask代码逻辑基本相同,下面将以MapTask为例)
- MapTaskRunnable的run方法如下
public void run() { try { // 1128794791_0001 // mapId {attempt_local1128794791_0001_m_000000_0} TaskAttemptID mapId = new TaskAttemptID(new TaskID( jobId, TaskType.MAP, taskId), 0); LOG.info("Starting task: " + mapId); mapIds.add(mapId); // systemJobFile {file:/tmp/hadoop-spencer/mapred/staging/root1128794791/.staging/job_local1128794791_0001/job.xml} // taskId {0} 后面的mapTask任务的taskId会逐一递增 // 创建MapTask MapTask map = new MapTask(systemJobFile.toString(), mapId, taskId, info.getSplitIndex(), 1); map.setUser(UserGroupInformation.getCurrentUser(). getShortUserName()); setupChildMapredLocalDirs(map, localConf); MapOutputFile mapOutput = new MROutputFiles(); mapOutput.setConf(localConf); mapOutputFiles.put(mapId, mapOutput); map.setJobFile(localJobFile.toString()); localConf.setUser(map.getUser()); map.localizeConfiguration(localConf); map.setConf(localConf); try { map_tasks.getAndIncrement(); myMetrics.launchMap(mapId); // 启动map的run方法 map.run(localConf, LocalJobRunner.Job.this); myMetrics.completeMap(mapId); } finally { map_tasks.getAndDecrement(); } LOG.info("Finishing task: " + mapId); } catch (Throwable e) { this.storedException = e; } }可见MapTaskRunnable主要任务是创建出MapTask,然后启动其map方法
至此,Job提交作业的大致流程,已及map任务和reduce任务是如何跑起来的已经基本弄清。