一. About Hive
- Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成一张数据库表,并提供类SQL查询功能
- Hive设计目的是让精通SQL技能(但Java编程技能相对较弱)的分析师能够对Facebook存放在HDFS中的大规模数据集执行查询。今天,Hive已经是一个成功的Apache项目,很多组织把它用作一个通用的,可伸缩的数据处理平台
二. Hive架构
- 架构图:
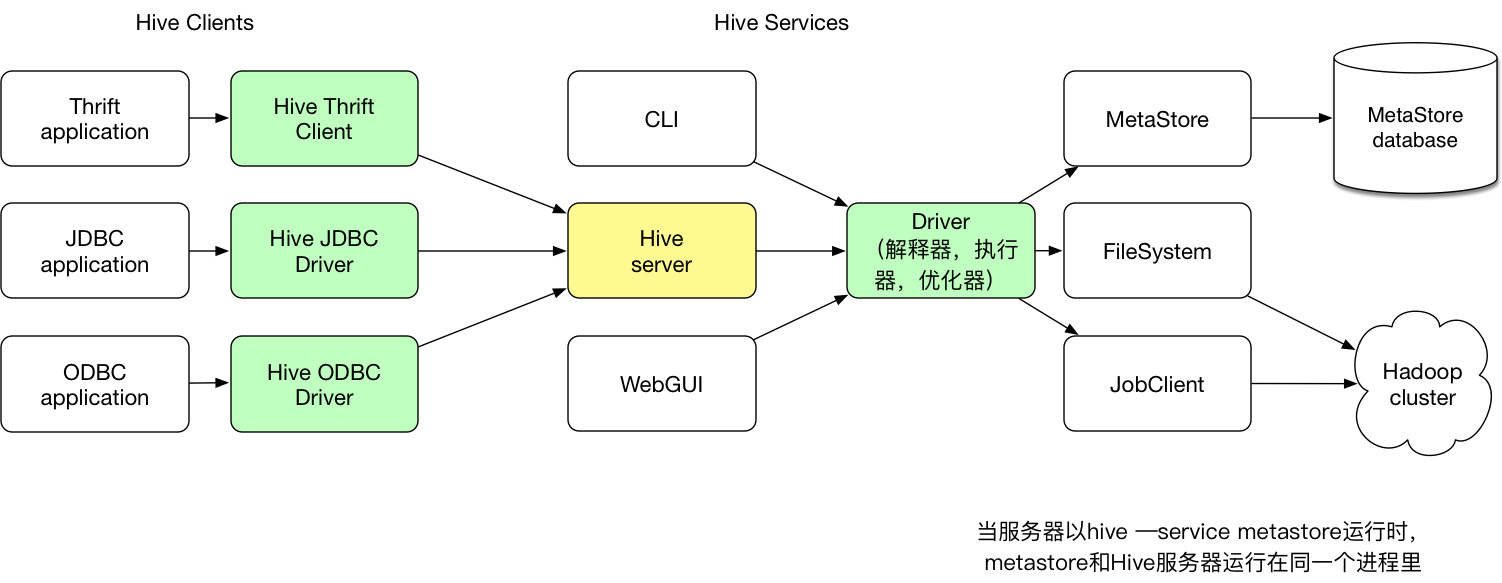
- 用户接口:包括CLI,JDBC/ODBC和WebGUI。最常用的是CLI,CLI在启动的时候会同时启动一个Hive副本。JDBC/ODBC是Hive的Java实现,与传统数据库JDBC类似
- 元数据存储:Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
- 解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行
- Hive的数据存储在HDFS中,大部分的查询,计算由MapReduce完成
三. Hive的数据存储
- Hive中所有的数据都存储在HDFS中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile等)
- 只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据
- Hive中包含以下数据模型:DB,Table,External Table, Partition,Bucket
- DB:在HDFS中表现为${hive.metastore.warehouse.dir}目录下的一个文件夹
- Table:在HDFS中表现所属DB目录下的一个文件夹
- External Table:外部表,和Table类似,不过其数据存放位置可以在任意指定路径。普通表删除后,HDFS上的文件和metastore中的元数据都会被删除。外部表被删除后,只有metastore中的元数据会被删除
- Partition:在HDFS上的表现形式为Table目录下的子目录
- Bucket:桶,在HDFS中表现形式为同一个表目录下根据Hash散列之后的多个文件,对列值取Hash值,将不同数据放到不同文件中存储