一. WordCount
- Driver
public class WordCountDriver { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); // 如果打包在集群上跑 不需要设置 // conf.set("mapreduce.framework.name", "yarn"); // conf.set("yarn.resourcemanager.zk-address", "hadoop2:2181,hadoop3:2181,hadoop4:2181"); Job job = Job.getInstance(conf); // 指定本业务job要使用的mapper/reducer业务类 job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); // 指定mapper输出数据的kv类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 指定最终输出的数据的kv类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 指定job的输入原始文件所在位置 Path inputPath = new Path("/wordcount/input"); FileInputFormat.addInputPath(job, inputPath); // 指定job的输出文件所在目录 Path outputPath = new Path("/wordcount/output"); FileOutputFormat.setOutputPath(job, outputPath); // 指定本程序的jar包所在的本地路径 // job.setJar("/home/hadoop/wc.jar"); 使用这种方式的话 不够灵活 job.setJarByClass(WordCountDriver.class); // 将job中配置的相关参数,以及job所在的java类所在的jar包,提交给yarn去运行 // job.submit(); boolean res = job.waitForCompletion(true); System.exit(res ? 0 : 1); } } - Mapper
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private Text word = new Text(); private IntWritable ONE = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer tokenizer = new StringTokenizer(value.toString()); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, ONE); } } } - Reducer
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count = 0; for (IntWritable value : values) { count += value.get(); } context.write(key, new IntWritable(count)); } } -
打包方式
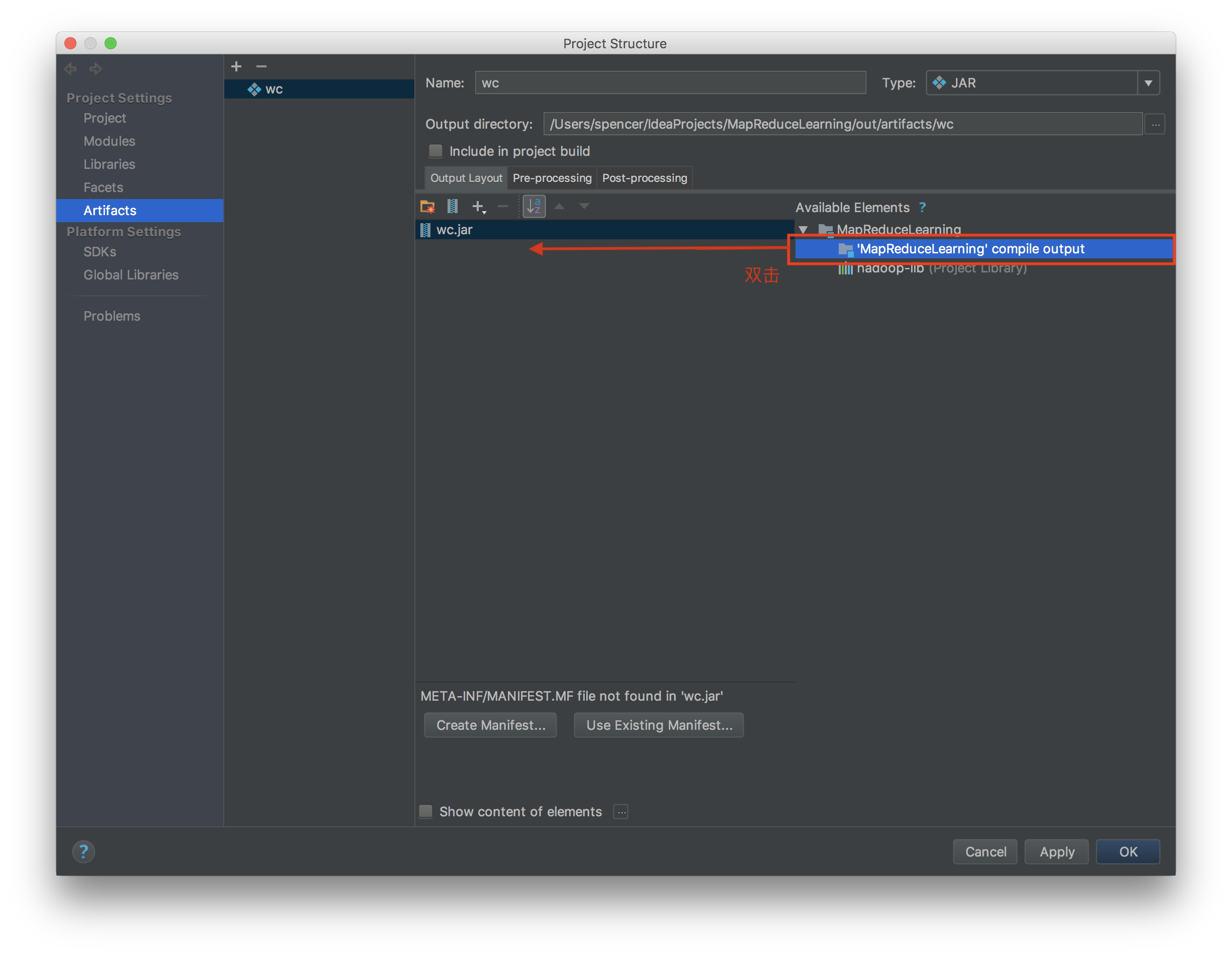
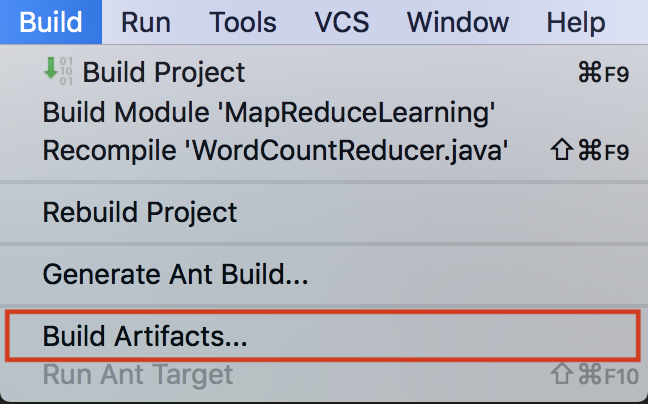
- 在集群上运行
$ hadoop jar wc.jar cn.itcast.bigdata.wordcount.WordCountDriver args