一. HDFS的概念
- NameNode
- NameNode负责管理整个文件系统的元数据,接受客户端的读写请求,收集DataNode汇报的Block列表信息
- NameNode基于内存存储,不会和磁盘发生交换
- NameNode的持久化通过fsimage和edits完成
- DataNode
- DataNode负责管理用户的文件数据块,启动DataNode会向NameNode发送Block信息
- 通过向NameNode发送心跳与其联系(3秒一次),如果NameNode10分钟没有收到DataNode心跳,则认为其已经lost,并将其上的Block块copy到其他DataNode
- HDFS特点
- 一次写入,多次读取,不支持修改文件(仅支持append)
- HDFS是为高数据吞吐量优化的,要求低时间延迟数据访问的应用(如几十毫秒)不适合在HDFS运行。目前,对于低延迟的访问需求,HBase是更好的选择
- 具有高容错性,数据存有多个副本(默认为3),某一节点副本丢失,自动拷贝到其他节点
- 适合大规模数据处理(GB,TB,PB)
- 可构建在廉价商用硬件上
二. HDFS写数据流程
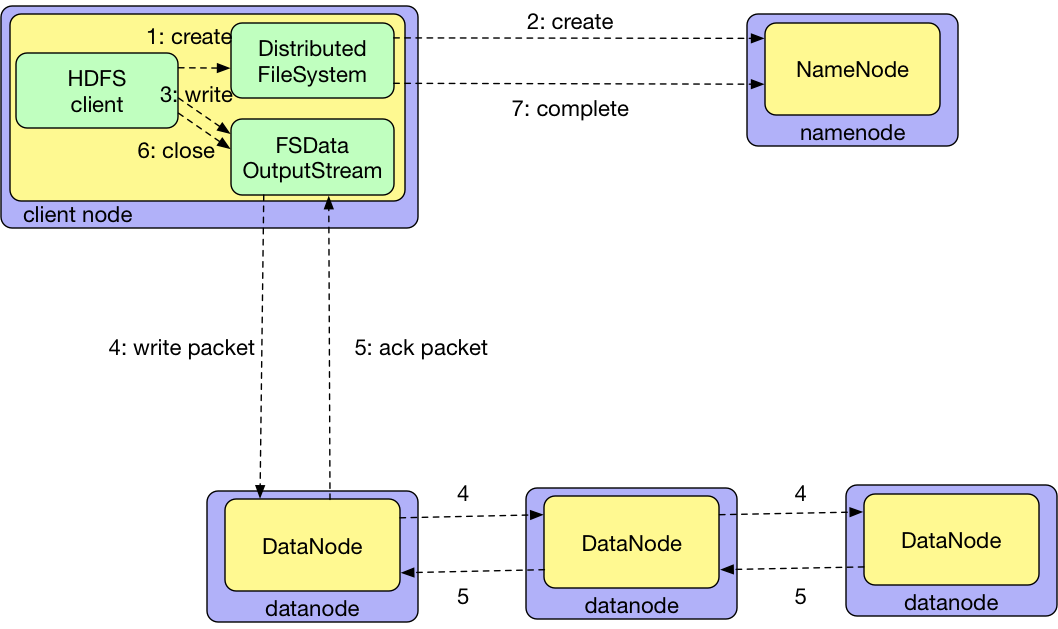
- 客户端对DistributedFileSystem对象调用create()方法新建文件
- DistributedFileSystem对NameNode创建一个RPC调用,在文件系统的命名空间中新建一个文件,并向客户端返回一个FSDataOutputStream对象。FSDataOutputStream封装一个DFSOutputStream对象,该对象负责处理DataNode和NameNode之间的通讯
- 客户端通过FSDataOutputStream写入数据时,DFSOutputStream将数据分成一个个的数据包(64k),写入内部数据队列
- DataStreamer处理数据队列,根据DataNode列表来要求NameNode分配新块来存储数据副本。这一组DataNode构成一个管线,假设副本数为3,管线中有3个节点。DataStreamer将数据包流式传输到管线中的第一个DataNode,该DataNode存储数据包并将它发送到管线中的第二个DataNode。同样,第二个DataNode存储该数据包并且发送给管线中的第三个DataNode
- DFSOutputStream也维护着一个内部数据包队列来等待DataNode的收到确认回执,称为“确认队列”。收到管线中所有DataNode确认信息后,该数据包才会从确认队列中删除
- 客户端完成数据写入后,对FSDataOutputStream调用close()方法
三. HDFS读数据流程
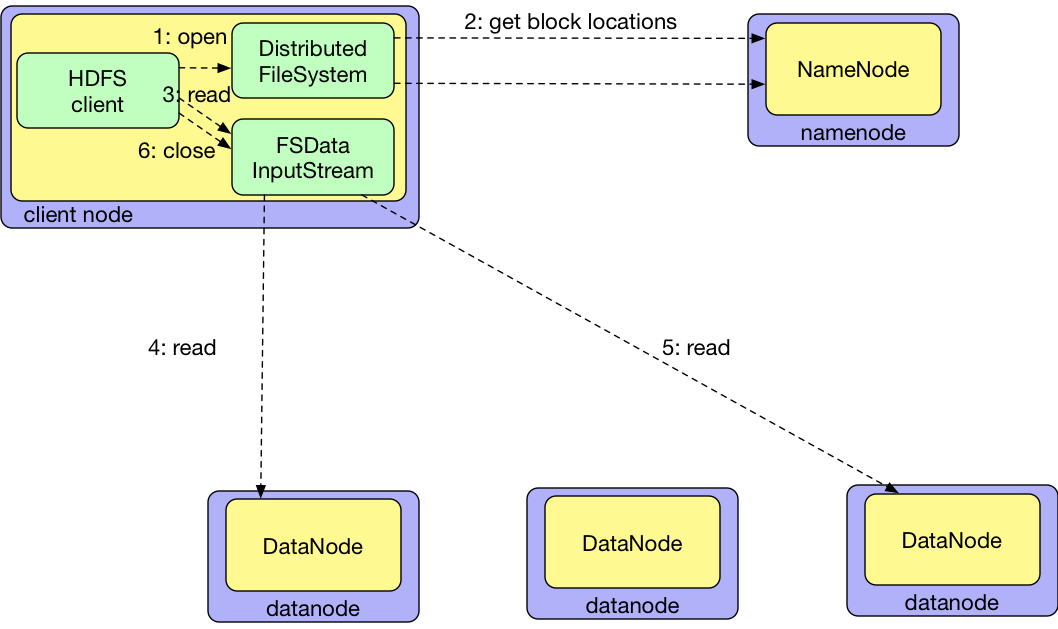
- 客户端通过调用DistributedFileSystem对象的open()方法来打开希望读取的文件
- DistributedFileSystem对NameNode创建一个RPC调用,获得文件起始块的位置。对于每一个块,NameNode返回存有该快副本的DataNode地址。DistributedFileSystem返回一个FSDataInputStream对象给客户端读取数据。FSDataInputStream封装DFSInputStream对象,该对象管理着DataNode和NameNode的IO
- 接着,客户端对FSDataInputStream调用read()方法
- 存储着文件起始几个块的DataNode地址的DFSInputStream随机连接距离最近的DataNode。通过对数据流反复调用read()方法,可以将数据从DataNode传输到客户端
- 到达块的末端时,DFSInputStream关闭与该DataNode的连接,然后寻找下一个块的最佳DataNode。客户端只需要读取连续的流,这些对于客户端都是透明的
- 客户端读取完成,对FSDataInputStream调用close()方法
四. 副本放置策略
- 在运行客户端的节点放第一个副本(如果客户端运行在集群外,就随机选择一个节点)
- 第二个副本跨机架挑选一个节点,增加副本可靠性
- 第三个副本和第二副本在同一机架上,且随机选择另一个节点